Identification ADN : le profil génétique

Après sa découverte Jeffreys emploie le terme de “dna fingerprint” que l’on pourrait traduire par “empreinte génétique”. Pour un individu, contrairement à ses empreintes digitales qui sont le reflet de la totalité de ses dix doigts, son empreinte génétique ne reflète qu’une petite partie de son ADN. Une fiche décadactylaire est composée de dix empreintes digitales toutes considérées comme individuelles alors que le résultat d’une analyse ADN se présente sous la forme d’une combinaison d’allèles qui sont chacun partagés par une partie de la population. Pour cette raison, le terme de “profil génétique” semble être plus approprié pour présenter le résultat d’une analyse ADN dont le résultat peut différer en fonction des marqueurs analysés et des kits multiplex utilisés.
Vu que ce ne sont pas deux molécules ADN qui sont comparées mais des zones infimes fragments de ces molécules, un rapprochement entre une trace et un individu ne pourra se faire qu’avec une interprétation statistique. Lorsque les résultats d’analyse entre une trace et un individu ne concordent pas et que l’on se trouve dans un cas simple (pas de contamination ou de mélange, quantité d’ADN suffisante) on peut facilement conclure à une exclusion. En revanche quand les résultats sont parfaitement compatibles, la conclusion ne peut pas être une identification formelle.
Un profil ADN ne  représente qu’une petite partie de la molécule ADN et il pourrait, en théorie, être partagé par une partie de la population. L’expert qui présente des résultats doit donc établir la probabilité d’observer un tel profil si la trace a été laissée par une autre personne que le suspect, soit la probabilité de correspondance fortuite. Pour cela il est indispensable d’utiliser la fréquence des génotypes au sein de la population. La fréquence des génotypes peut se calculer à partir de la fréquence des allèles. Les fréquences des allèles au sein d’une population sont bien connues, de nombreuses données ont été publiées par des laboratoires ou dans des revues internationales.
représente qu’une petite partie de la molécule ADN et il pourrait, en théorie, être partagé par une partie de la population. L’expert qui présente des résultats doit donc établir la probabilité d’observer un tel profil si la trace a été laissée par une autre personne que le suspect, soit la probabilité de correspondance fortuite. Pour cela il est indispensable d’utiliser la fréquence des génotypes au sein de la population. La fréquence des génotypes peut se calculer à partir de la fréquence des allèles. Les fréquences des allèles au sein d’une population sont bien connues, de nombreuses données ont été publiées par des laboratoires ou dans des revues internationales.
Pour présenter le résultat d’une comparaison ADN, l’approche Bayésienne, qui donne un cadre scientifique à l’interprétation des résultats, est la plus adaptée. Cette approche repose sur la mise en compétition de deux hypothèses alternatives :
Hp : Il s’agit de l’hypothèse du procureur (de l’accusation) selon laquelle le suspect est à l’origine de la trace ADN.
Hd : Il s’agit de l’hypothèse de la défense selon laquelle une autre personne que le suspect est à l’origine de la trace ADN.
La formule mathématique inspiré du mathématicien Thomas Bayes permet d’ajuster les convictions de chacun en fonction des indices matériels recueillis sur la scène de crime. Cela permet une évaluation complète en associant l’information analytique de l’expert et l’information, collectée pendant la phase d’enquête, sur les circonstances de l’affaire.

I : Informations générales sur le cas, circonstances de l’affaire
E : Evidence, concordance entre une trace et le matériel de comparaison
P (E/Hp,I) : Concerne la probabilité d’observer “ce profil génétique” sachant l’hypothèse du procureur et les informations du cas
P (E/Hd,I) : Concerne la probabilité d’observer “ce profil génétique” sachant l’hypothèse de la défense et les informations du cas
L’expert s’exprime donc uniquement sur la valeur de l’indice matériel
L’expert n’a pas connaissance de toutes les circonstances particulières du cas et ne peut pas évaluer correctement les chances en faveur ou en défaveur des hypothèses posées par la cour. L’expert s’exprime donc uniquement sur la valeur de l’indice matériel, à l’aide du “rapport de vraisemblance” ou Likelihood ratio (LR) :

Le résultat de ce calcul permettra de soutenir une des deux hypothèses mises en opposition :
Si LR = 1
la preuve n’est pas pertinente car elle tend aussi bien en faveur de la défense que de l’accusation
Si LR < 1 le résultat soutien l’hypothèse de la défense Hd par rapport à Hp
Si LR > 1 le résultat soutien l’hypothèse du procureur Hp par rapport à Hd
Les hypothèses seront ensuite plus ou moins fortement soutenues en fonction de la valeur du LR.
La probabilité donnée par l’expert est combinée avec la probabilité “a priori” qui est la probabilité d’un événement avant la phase d’expertise. Cette probabilité est évalué par le juge, les avocats, les jurés à partir des données d’enquête comme des témoignages, aveux…
Dans un cas simple, pour évaluer le résultat d’une analyse ADN les deux hypothèses mises en concurrence pourront être :
Hp : le suspect est à l’origine de la trace
Hd : un autre individu que le suspect est à l’origine de la trace
Prenons l’exemple d’un profil ADN “partiel” obtenu avec l’analyse de seulement trois marqueurs (TPOX, TH01 et VWA). Une trace analysée possède les allèles 8 et 8 sur le marqueur TPOX, 6 et 7 sur le marqueur TH01, 5 et 8 sur le marqueur VWA. Le suspect possède ces mêmes allèles pour ces mêmes marqueurs, la probabilité que le suspect soit à l’origine de la trace est donc de 1 = P(E/Hp)
D’après une étude de population adéquate, la probabilité d’obtenir les allèles 8 et 8 pour le marqueur TPOX est de 0,28. La probabilité d’obtenir les allèles 6 et 7 pour le marqueur TH01 est de 0,07. La probabilité d’obtenir les allèles 5 et 8 pour le marqueur VWA est de 0,05. En supposant que les probabilités sont indépendantes, la probabilité d’obtenir ces allèles simultanément pour ces trois marqueurs est donc de 0,28 x 0,07 x 0,05 = 0,00098 = P (E/Hd).
Ce qui nous permet de déterminer la valeur du rapport de vraisemblance comme étant le suivant :
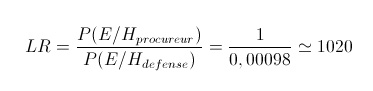
Ce rapport de vraisemblance nous indique qu’il est environ 1000 fois plus vraisemblable d’observer ce profil si le suspect est la source de la trace plutôt que quelqu’un d’autre.
 En augmentant le nombre de marqueurs analysés, on augmente considérablement la force du rapport de vraisemblance. Avec 10 marqueurs analysés on arrive à une probabilité fortuite d’apparition du génotype de 1 sur plusieurs centaines de milliards ce qui permet de conclure à une identification “quasi formelle” de l’individu comme étant la source de la trace. Toutefois la valeur du rapport de vraisemblance et donc de la force de la preuve va baisser lorsque l’on se trouve en présence d’un mélange ou lorsque l’on applique la méthode LCN (Low Copy Number)
En augmentant le nombre de marqueurs analysés, on augmente considérablement la force du rapport de vraisemblance. Avec 10 marqueurs analysés on arrive à une probabilité fortuite d’apparition du génotype de 1 sur plusieurs centaines de milliards ce qui permet de conclure à une identification “quasi formelle” de l’individu comme étant la source de la trace. Toutefois la valeur du rapport de vraisemblance et donc de la force de la preuve va baisser lorsque l’on se trouve en présence d’un mélange ou lorsque l’on applique la méthode LCN (Low Copy Number)
Bien que particulièrement discriminante, la méthode d’identification par l’ADN n’en reste pas moins faillible et soumise à l’erreur humaine. Pas du fait de la technique ou de l’interprétation des résultats mais plus du fait de l’intervention humaine à tous les niveaux : prélèvement, conditionnement et autres manipulations qui peuvent provoquer des inversions d’échantillons ou des contaminations.
Découvrez les affaires dans lesquelles l’identification de l’ADN a joué un rôle primordial :








