L’image numérique
L’image numérique est constituée d’un ensemble de points appelés pixels. Un pixel (abrévation de PICture ELement) est défini comme le plus petit élément constitutif d’une image numérique matricielle. Pour une image à deux tons, noir et blanc, le pixel peut être codé par un seul bit codant (0 pour noir ou 1 pour blanc). Pour des images en nuances de gris ou en couleurs le pixel peut être codé par 2, 4, 8, 16, 24 ou 32 bits.
Définition des images numériques et pixellisation
![]() Plus l’image possède de pixels plus la “définition” de l’image est importante. En effet, la définition d’une image est définie comme le nombre total de pixels composant une image numérique. Plus le nombre de pixels est important plus la qualité de la photographie brute est bonne. Le nombre de pixels est directement lié à la qualité du capteur et de l’appareil photographique. L’image en très haute définition donnera davantage une image riche en détail et favorisera la possibilité d’agrandissement de l’image. Chaque appareil photographique numérique possède sa définition optimale (il existe des appareils haute définition à plus de 50Mp) mais il est possible de régler directement sur l’appareil d’autres définitions plus faibles (pour ne pas saturer trop rapidement la carte mémoire).
Plus l’image possède de pixels plus la “définition” de l’image est importante. En effet, la définition d’une image est définie comme le nombre total de pixels composant une image numérique. Plus le nombre de pixels est important plus la qualité de la photographie brute est bonne. Le nombre de pixels est directement lié à la qualité du capteur et de l’appareil photographique. L’image en très haute définition donnera davantage une image riche en détail et favorisera la possibilité d’agrandissement de l’image. Chaque appareil photographique numérique possède sa définition optimale (il existe des appareils haute définition à plus de 50Mp) mais il est possible de régler directement sur l’appareil d’autres définitions plus faibles (pour ne pas saturer trop rapidement la carte mémoire).
Ainsi dans l’exemple de l’appareil photographique Nikon D3200, le capteur peut permettre d’obtenir des définitions de (Largeur d’image) x (Hauteur d’image) :
- Mode haute définition : 6016 pixels x 4000 pixels = 24064000 pixels soit environ 24Mp
- Mode moyenne définition : 4512 pixels x 3000 pixels= 13536000 pixels soit environ 13,5Mp
- Mode basse définition : 3008 pixels x 2000 pixels = 6016000 soit environ 6Mp
Si l’image possède une définition trop faible son agrandissement peut provoquer la pixellisation de l’image. Le choix de la définition est donc directement lié à ce que l’on veut faire de l’image. Le problème de la pixellisation se pose souvent lors du visionnage des images des caméras de vidéo-surveillance par les services d’enquête.
Une image qui possède à la base une mauvaise définition ne pourra pas voir sa qualité de détail s’améliorer, et cela même, avec des logiciels de traitement d’image et les opérations d’agrandissement, de modification de la luminosité, des couleurs ou du contraste. Par exemple, les images extraites des vidéosurveillances des centres urbains, bien que très informatives, ne permettent pas souvent de déterminer l’immatriculation des véhicules (bien que des techniques spécifiques corrigent parfois ce problème). Le zoom sur la plaque ou l’amélioration de la luminosité ne permettront pas de créer de l’information qui n’existe pas à la base. Initialement, si l’on dispose d’une image de 32 pixels avec une information de chrominance et de luminance sur chaque pixel, il est illusoire de penser que la création de 32 pixels supplémentaires avec un logiciel donnera de l’information là où il n’y en a pas. Les 32 pixels supplémentaires peuvent effectivement être créés mais ils le seront à partir des données des pixels existants. Il s’agit du processus d“interpolation”. Ce processus est formellement interdit ou fortement déconseillé dans l’exploitation des photographies de traces digitales puisqu’il modifie la réalité de l’image. Les pixels créés sont “fictifs”, ils ne correspondent pas à la réalité de l’image. Voici une bonne explication du processus d’interpolation. Sur les images ci-dessous, on peut observer l’effet de l’augmentation de la définition :

Poids d’une image sur son support numérique et format d’enregistrement
Le poids du fichier numérique créé va directement dépendre de la définition de l’image. Plus la définition est importante plus le poids initial sera élevé. Le poids du fichier numérique dépendra également d’autres facteurs réglables directement sur l’appareil photographique comme le format d’enregistrement de l’image et la profondeur de couleur.
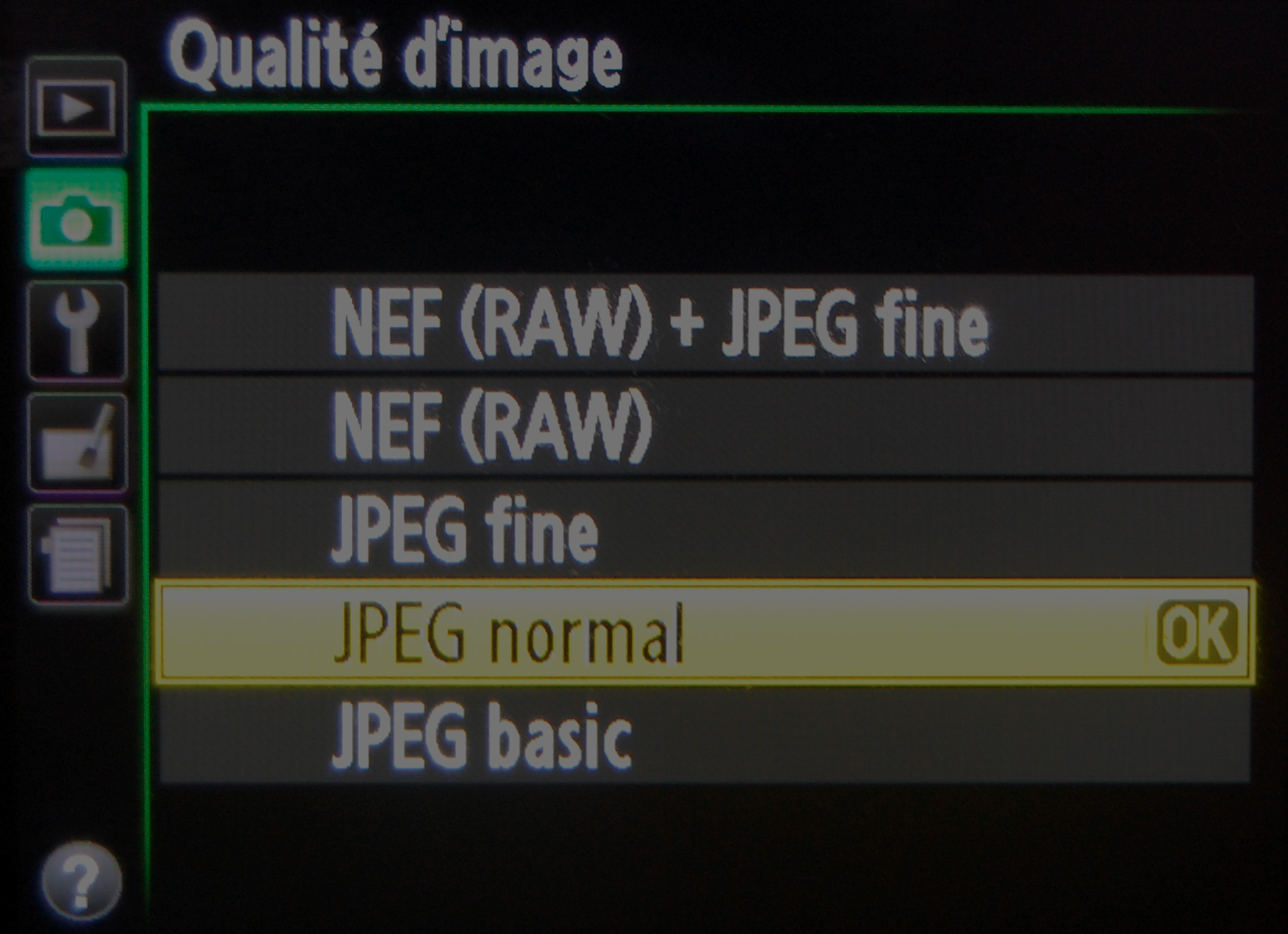 Les formats d’enregistrement disponibles directement sur l’appareil photographique sont le RAW et le JPEG (fine, normal ou basic).
Les formats d’enregistrement disponibles directement sur l’appareil photographique sont le RAW et le JPEG (fine, normal ou basic).
Le JPEG est un format qui compresse l’image. Il est le plus couramment utilisé en photographie numérique car il offre un excellent rapport entre poids et qualité d’image. Ce format peut être utilisé avec différents niveaux de compression (fine, normal ou basic) chaque niveau réduisant la taille du fichier mais aussi la qualité de l’image. De par son fonctionnement, l’utilisation de la compression JPEG réduit la profondeur de couleur de l’image et crée des blocs d’une même couleur éliminant les nuances intermédiaires.
Le RAW est un format “brut” qui délivre les informations directement issues du capteur. Le format RAW enregistre directement les informations données sans les traiter. Il en résulte l’obtention d’image de qualité mais d’un poids non négligeable (pouvant parfois dépasser les 50Mo pour les appareils dont la définition est supérieure à 20Mpixels).
Des logiciels de traitement d’image offrent la possibilité de transformer un fichier RAW en une image TIFF, GIF, BMP ou encore PNG.
Format TIFF : format sans compression ou avec compression LZW qui restaure l’image sans perte de détail ou de qualité. L’inconvénient de ce format est le poids très important du fichier créé.

Format GIF : format qui offre une image compressée tout en gardant bon rendu mais qui reste limité au niveau de la profondeur de couleur (limité à 256 couleurs). Ce format permet la réalisation d’images animées.
Format BMP (ou Bitmap) : format par defaut de microsoft windows qui offre un fichier sans compression et par conséquent très lourd.
Format PNG : format qui offre une excellente compression sans perte
Le choix du format devra se faire en fonction de la qualité d’image désirée, de l’économie de place sur le support d’enregistrement, de la facilité à retoucher l’image ou encore de sa pérennité.
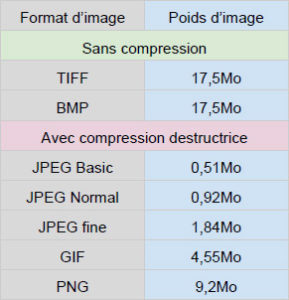
Par exemple pour un même cliché réalisé en format RAW d’un poids initial de 6,04Mo, les poids des fichiers créés sont les suivants :
 Après le réglage de la définition et du format d’image, la profondeur de couleur est l’autre paramètre réglable directement sur l’appareil photographique. Dans les réglages du menu, le photographe peut choisir de régler directement les tons et les couleurs de la photographie, comme dans le “picture control” chez Nikon. Cette profondeur de couler permet de jouer sur la taille et la qualité de l’image photographique. La profondeur de couleur, exprimée en bits, est le nombre de tons ou de couleurs que peut prendre un pixel.
Après le réglage de la définition et du format d’image, la profondeur de couleur est l’autre paramètre réglable directement sur l’appareil photographique. Dans les réglages du menu, le photographe peut choisir de régler directement les tons et les couleurs de la photographie, comme dans le “picture control” chez Nikon. Cette profondeur de couler permet de jouer sur la taille et la qualité de l’image photographique. La profondeur de couleur, exprimée en bits, est le nombre de tons ou de couleurs que peut prendre un pixel.
– Lorsque la profondeur de couleur est de 1 bit, chaque pixel de l’image peut avoir deux valeurs : 0 ou 1. Le 0 correspond au noir et le 1 correspond au blanc. L’image crée sera alors en noir et blanc.
– Lorsque d’autres bits sont utilisés pour décrire chaque pixel, d’autres tons (gris) vont se placer entre le noir et le blanc. Ainsi pour une résolution de 2 bits 22= 4 tons pourront être créés le noir, le blanc et 2 tonalités grises avec les codages 00, 01, 10, et 11.
– Pour une profondeur de couleur de 8 bits (un octet) le pixel peut prendre 28 = 256 tons de gris ou de couleur.
– La création d’une photographie couleur se fait par une synthèse additive des couleurs Rouge Vert et Bleu (RVB). Chaque couleur est codée avec 256 niveaux et c’est le mélange de ces trois couleurs qui va créer la couleur finale. Le pixel est donc codé avec un mélange de 3 couleurs à 256 niveaux (2563) ce qui fait environ 16 millions de couleurs
– Il existe d’autres systèmes chromatiques tel que le CMJN (Cyan, Magenta, Jaune et Noir) qui est une synthèse soustractive utilisée pour l’impression en Quadrichromie. Le codage s’effectue sur 32 bits.
Plus le nombre de bits utilisé est grand et plus l’image numérique créée possédera des couleurs en adéquation avec la réalité. En revanche le poids de l’image créée sera plus important.
Résolution et taille d’impression d’une image numérique
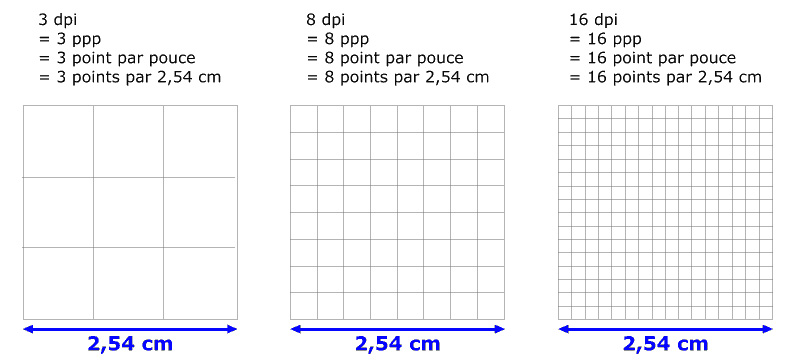
A ne pas confondre avec la définition qui représente un nombre total de pixels, la résolution représente un nombre de pixels par unité de surface. Il s’agit d’une densité. Elle est exprimée en dpi (dot per inch) ou ppp (pixels par pouce). La résolution prend tout son sens lorsque l’image est imprimée sur un support physique. Un pouce mesure 2,54cm ce qui signifie que pour une résolution de 16ppp l’image imprimée est composée de 16 pixels pour 2,54cm de largeur et 16 pixels pour 2,54cm de hauteur soit un carré de 16×16 = 256 pixels.
Une résolution de 300ppp signifie qu’une ligne de 2,54cm est composée de 300 pixels, la taille d’un pixel est ainsi d’environ 0,085mm (2,54cm/300). Au vu du pouvoir séparateur de l’oeil (capacité à séparer visuellement deux objets distincts) cette résolution est celle nécessaire pour offrir un rendu assez proche d’une photographie argentique classique d’un format de 10x15cm et pour que l’oeil ne distingue pas les pixels en observant l’image imprimée d’une distance de plus de 20cm.
Les scanners sont également capable de discerner des détails plus ou moins fins. Lorsqu’un scanner numérise une image à 500dpi, c’est qu’il est capable de discerner 500 pixels tous les 2,54cm.
La définition initialement choisie lors d’un scan ou d’une photographie conditionne la qualité ou la taille de l’impression. Plus la photographie aura une bonne définition initiale et plus la photographie imprimée pourra être de grande taille ou plus sa résolution pourra être de meilleure qualité :


Ainsi pour une définition de 1,5Mpixels la taille maximale de l’impression à 300ppp sera de 12,7 x 8,5 cm. Pour une définition de 6Mpixels la taille de l’image imprimée à 300ppp pourra être deux fois plus grande sans pour autant perdre en qualité.
Si la définition choisie initialement est trop faible, il est possible d’augmenter le nombre de pixels du cliché mais cela revient à créer de l’information là où elle n’existe pas initialement. Cette opération de “rééchantillonnage” est proscrite par les services de police.














